Code
library(stringr)
library(gt)
library(dplyr)
library(ggplot2)
library (tidyverse)
library(DT)
library(knitr)
library(readxl)
library(readr)
library(data.table)For this project, we will analyze data from the Internet Movie Database (IMDb), one of the most comprehensive and widely-used sources for movie-related information. We will leverage the IMDb non-commercial release, which provides access to extensive data on films, directors, actors, ratings, and much more. This dataset, made freely available by IMDb for non-commercial use, offers a wealth of information that will allow us to explore key aspects of the film industry, such as movie success metrics, trends across genres, and the careers of notable actors and directors. Our analysis will aim to uncover meaningful insights from this rich dataset and create an elevator pitch for the best successful movie ever.
First, let’s start by downloading the packages that we will need for our code:
library(stringr)
library(gt)
library(dplyr)
library(ggplot2)
library (tidyverse)
library(DT)
library(knitr)
library(readxl)
library(readr)
library(data.table)Then, we will download the data sets. Because those are large files, we will upload those files from this GitHub page.
##loading the data files
get_imdb_file <- function(fname){
BASE_URL <- "https://datasets.imdbws.com/"
fname_ext <- paste0(fname, ".tsv.gz")
if(!file.exists(fname_ext)){
FILE_URL <- paste0(BASE_URL, fname_ext)
download.file(FILE_URL,
destfile = fname_ext)
}
as.data.frame(readr::read_tsv(fname_ext, lazy=FALSE))
}
NAME_BASICS <- get_imdb_file("name.basics")
TITLE_BASICS <- get_imdb_file("title.basics")
TITLE_EPISODES <- get_imdb_file("title.episode")
TITLE_RATINGS <- get_imdb_file("title.ratings")
TITLE_CREW <- get_imdb_file("title.crew")
TITLE_PRINCIPALS <- get_imdb_file("title.principals")This data is large enough that we’re going to need to immediately start down-selecting to get to a data set that we can analyze fluidly. We are going throw out any title with less than 100 ratings and any data that is related to those titles with the following code:
NAME_BASICS <- NAME_BASICS |>
filter(str_count(knownForTitles, ",") > 1)
TITLE_RATINGS <- TITLE_RATINGS |>
filter(numVotes >= 100)
TITLE_BASICS <- TITLE_BASICS |>
semi_join(TITLE_RATINGS,
join_by(tconst == tconst))
TITLE_CREW <- TITLE_CREW |>
semi_join(TITLE_RATINGS,
join_by(tconst == tconst))
TITLE_EPISODES_1 <- TITLE_EPISODES |>
semi_join(TITLE_RATINGS,
join_by(tconst == tconst))
TITLE_EPISODES_2 <- TITLE_EPISODES |>
semi_join(TITLE_RATINGS,
join_by(parentTconst == tconst))
TITLE_EPISODES <- bind_rows(TITLE_EPISODES_1,
TITLE_EPISODES_2) |>
distinct()
TITLE_PRINCIPALS <- TITLE_PRINCIPALS |>
semi_join(TITLE_RATINGS, join_by(tconst == tconst))
rm(TITLE_EPISODES_1)
rm(TITLE_EPISODES_2)Now, let’s start exploring our data and correct the column types of the TITLE tables using a combination of mutate and the coercion functions as.numeric and as.logical. NAME_BASICS table:
NAME_BASICS <- NAME_BASICS |>
mutate(
birthYear = as.numeric(birthYear),
deathYear = as.numeric(deathYear)
)
# Let's view data now.
glimpse(NAME_BASICS)TITLE_BASICS Table:
TITLE_BASICS <- TITLE_BASICS |>
mutate(
startYear = as.numeric(startYear),
endYear = as.numeric(endYear),
runtimeMinutes = as.numeric(runtimeMinutes),
isAdult = as.logical(isAdult)
)
glimpse(TITLE_BASICS)TITLE_EPISODES Table:
TITLE_EPISODES <- TITLE_EPISODES |>
mutate(
seasonNumber = as.numeric(seasonNumber),
episodeNumber = as.numeric(episodeNumber)
)
glimpse(TITLE_EPISODES)Now let’s answer some questions to get more insights out of those data sets in order to conduct our analyzes.
1.How many movies are in our data set? How many TV series? How many TV episodes?
num_movies <- TITLE_BASICS |>
filter(titleType == "movie") |>
count()
num_tv_series <- TITLE_BASICS |>
filter(titleType == "tvSeries") |>
count()
num_tv_episodes <- TITLE_BASICS |>
filter(titleType == "tvEpisode") |>
count()
result_table <- tibble(
Category = c("Movies", "TV Series", "TV Episodes"),
Count = c(num_movies$n, num_tv_series$n, num_tv_episodes$n)
)
result_table %>%
gt() %>%
tab_header(title = "Internet Movie Database (IMDb)") %>%
fmt_number(
columns = vars(Count),
decimals = 0
)| Internet Movie Database (IMDb) | |
|---|---|
| Category | Count |
| Movies | 132,642 |
| TV Series | 30,110 |
| TV Episodes | 157,447 |
2.Who is the oldest living person in our data set?
current_year = 2024
oldest_living_person <- NAME_BASICS |>
filter(is.na(deathYear)) |>
filter(birthYear >= (current_year - 124)) |>
arrange(birthYear) |>
select(- nconst,
- knownForTitles) |>
slice(1)
oldest_living_person |>
gt() |>
tab_header(title = "Oldest Living Person")| Oldest Living Person | |||
|---|---|---|---|
| primaryName | birthYear | deathYear | primaryProfession |
| Léonide Azar | 1900 | NA | editor,director,miscellaneous |
The oldest living person in our data set is Léonide Azar. He was born on March 20th in 1900 in St Petersburg, Russia. He is known for Elevator to the Gallows, Love in the Afternoon and Riff Raff Girls.
There is one TV Episode in this data set with a perfect 10/10 rating and at least 200,000 IMDb ratings. 3.What is it? What series does it belong to?
# Function to find the primaryTitle using a tconst
find_primary_title <- function(selected_tconst, TITLE_EPISODE, TITLE_BASICS) {
# Step 1: Find the parentTconst of the selected tconst in TITLE_EPISODE
parentTconst <- TITLE_EPISODE$parentTconst[TITLE_EPISODE$tconst == selected_tconst]
# Step 2: Look up the parentTconst in TITLE_BASICS to find the primaryTitle
primaryTitle <- TITLE_BASICS$primaryTitle[TITLE_BASICS$tconst == parentTconst]
# Step 3: Return the primaryTitle
return(primaryTitle)
}
perfect_episode <- TITLE_RATINGS |>
filter(averageRating == 10, numVotes > 200000) |>
left_join(TITLE_BASICS, by = "tconst") |>
filter(titleType == "tvEpisode") |>
select(primaryTitle, titleType, genres, numVotes, tconst) |>
arrange(desc(numVotes)) |>
# Step 4: Add a new column for the parentTitle
mutate(parentTitle = sapply(tconst, find_primary_title, TITLE_EPISODES, TITLE_BASICS))
# Display the results in a table
perfect_episode |>
select(primaryTitle, parentTitle, titleType, genres, numVotes) |>
gt() |>
tab_header(
title = "TV Episode rated 10/10"
) |>
cols_label(
primaryTitle = "Episode Title",
parentTitle = "Parent Title",
titleType = "Title Type",
genres = "Genres",
numVotes = "Number of Votes"
)| TV Episode rated 10/10 | ||||
|---|---|---|---|---|
| Episode Title | Parent Title | Title Type | Genres | Number of Votes |
| Ozymandias | Breaking Bad | tvEpisode | Crime,Drama,Thriller | 231016 |
The answer is the episode named Ozymandias from the serie Breaking Bad. This episodes received 227589 ratings on IMDb.
4.What four projects is the actor Mark Hamill most known for?
# Step 1: filter Mark Hamill episodes titles
mark_hamill <- NAME_BASICS |>
filter(primaryName == "Mark Hamill") |>
pull(knownForTitles)
# Step 2: Split the knownForTitles string into individual tconsts
tconsts <- unlist(strsplit(mark_hamill, ","))
# Step 3: Filter TITLE_BASICS for Mark Hamill's known projects and add a ranking column
known_projects <- TITLE_BASICS |>
filter(tconst %in% tconsts) |>
select(primaryTitle, titleType, startYear) |>
arrange(desc(startYear)) |> # Sort by startYear in descending order
mutate(Rank = row_number()) |>
select(Rank, primaryTitle, titleType, startYear) # Rearrange columns to make Rank the first column
# Step 4: Display the table using gt with the ranking column as the first column
known_projects |>
gt() |>
tab_header(
title = "Top Projects of Mark Hamill"
) |>
cols_label(
Rank = "Rank",
primaryTitle = "Project Title",
titleType = "Type of Project",
startYear = "Start Year"
) |>
tab_options(
table.width = pct(100) # Set table width to 100%
)| Top Projects of Mark Hamill | |||
|---|---|---|---|
| Rank | Project Title | Type of Project | Start Year |
| 1 | Star Wars: Episode VIII - The Last Jedi | movie | 2017 |
| 2 | Star Wars: Episode VI - Return of the Jedi | movie | 1983 |
| 3 | Star Wars: Episode V - The Empire Strikes Back | movie | 1980 |
| 4 | Star Wars: Episode IV - A New Hope | movie | 1977 |
Mark Richard Hamill is an American actor who is know for his character as Luke Skywalker in the Star Wars franchise.
5.What TV series, with more than 12 episodes, has the highest average rating?
# Step 1: Filter for TV episodes with ratings and join with TITLE_BASICS
episode_ratings <- TITLE_EPISODES |>
inner_join(TITLE_RATINGS, by = "tconst") |>
inner_join(TITLE_BASICS, by = c("parentTconst" = "tconst"))
# Step 2: Count episodes per series and filter for series with more than 12 episodes
top_rated_series <- episode_ratings |>
group_by(parentTconst, primaryTitle) |>
summarise(
avg_rating = mean(averageRating, na.rm = TRUE),
num_episodes = n(),
.groups = "drop"
) |>
filter(num_episodes > 12) |>
arrange(desc(avg_rating)) |>
slice(1) # Select only the top one series
# Step 3: Display the result as a table using gt
top_rated_series |>
select(primaryTitle, num_episodes, avg_rating) |>
rename(
"Serie Title" = primaryTitle,
"Number of Episodes" = num_episodes,
"Average Rating" = avg_rating
) |>
gt() |>
tab_header(
title = "Top TV Serie by Average Rating"
) |>
cols_label(
`Serie Title` = "Serie Title",
`Number of Episodes` = "Number of Episodes",
`Average Rating` = "Average Rating"
) |>
fmt_number(
columns = vars(`Average Rating`),
decimals = 2 # Display 2 decimal places for the average rating
) |>
tab_options(
table.width = pct(100)
)| Top TV Serie by Average Rating | ||
|---|---|---|
| Serie Title | Number of Episodes | Average Rating |
| Kavya - Ek Jazbaa, Ek Junoon | 113 | 9.75 |
6.The TV series Happy Days (1974-1984) gives us the common idiom “jump the shark”. The phrase comes from a controversial fifth season episode (aired in 1977) in which a lead character literally jumped over a shark on water skis. Idiomatically, it is used to refer to the moment when a once-great show becomes ridiculous and rapidly looses quality. Is it true that episodes from later seasons of Happy Days have lower average ratings than the early seasons?
# Find all episodes of Happy Days
happy_days <- TITLE_BASICS |>
filter(primaryTitle == "Happy Days")
# Join with episodes and ratings
happy_days_ratings <- TITLE_EPISODES |>
filter(parentTconst %in% happy_days$tconst) |>
inner_join(TITLE_RATINGS, by = "tconst") |>
group_by(seasonNumber) |>
summarise(avg_rating = mean(averageRating, na.rm = TRUE)) |>
arrange(seasonNumber)
# Convert seasonNumber to a factor with custom labels
happy_days_ratings$seasonNumber <- factor(happy_days_ratings$seasonNumber,
labels = paste0("Season ", happy_days_ratings$seasonNumber))
# Create a bar chart to visualize the average ratings by season
ggplot(happy_days_ratings, aes(x = seasonNumber, y = avg_rating)) +
geom_bar(stat = "identity", fill = "skyblue") + # Use geom_bar for bar chart
labs(
title = "Average Episodes Ratings of Happy Days by Season",
x = "Seasons",
y = "Average Rating"
) +
scale_x_discrete(drop = FALSE) + # Ensure all factors are shown
theme_minimal()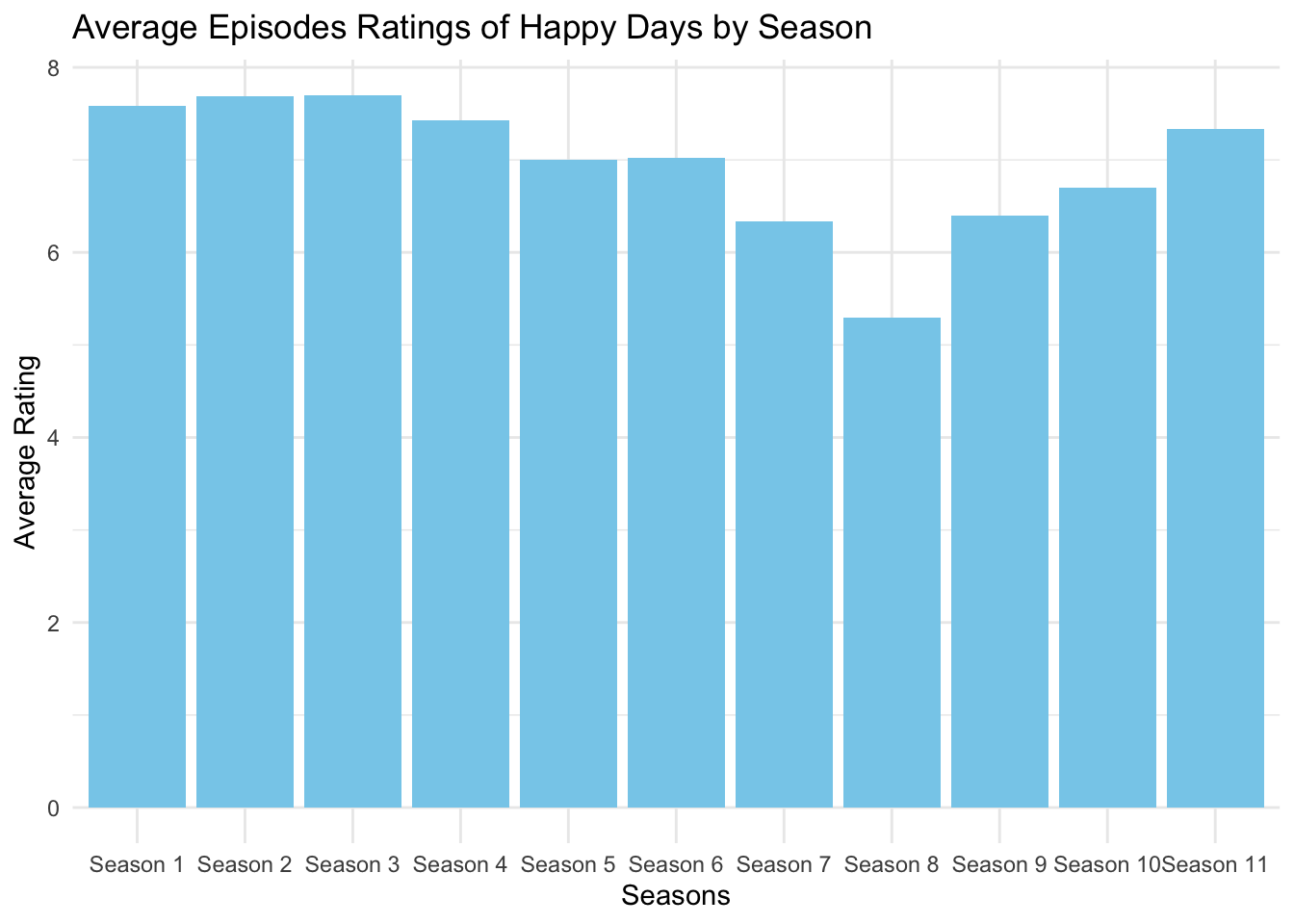
From the results shown on the graph, we can clearly see that the rating of the serie has declined from Season 5 and gained back success in Season 9.
Our goal is to proposal successful new movies. To do so, we need a way of measuring the success of a movie given only IMDb ratings. While there’s no “magic number” for success, it is logical to assume that a successful project will have both a high average IMDb rating, indicating quality, and a large number of ratings, indicating broad awareness in the public.
This code will design a ‘success’ measure for IMDb entries, reflecting both quality and broad popular awareness and implement the success metric using a mutate operator to add a new column to the TITLE_RATINGS table:
TITLE_RATINGS <- TITLE_RATINGS |>
mutate(success_metric = averageRating * log10(numVotes))Let’s know validate our success metric by realising some verification taks.
1.We are going to choose the top 10 movies on our metric and confirm that they were indeed box office successes.
# Filter for movies only
movies_only <- TITLE_BASICS |>
filter(titleType == "movie")
# Add a custom success metric to the movies_ratings table
movies_ratings <- TITLE_RATINGS |>
inner_join(movies_only, by = "tconst")
# View the top 10 movies by success_metric and create a visual table
top_movies_table <- movies_ratings |>
arrange(desc(success_metric)) |>
head(10) |>
select(primaryTitle, averageRating, numVotes, success_metric) |>
gt() |>
tab_header(
title = "Top 10 Movies by Success Metric",
subtitle = "Ranked from Highest to Lowest Success Metric"
) |>
cols_label(
primaryTitle = "Movie Title",
averageRating = "Average Rating",
numVotes = "Number of Votes",
success_metric = "Success Metric"
) |>
fmt_number(
columns = vars(averageRating, numVotes, success_metric),
decimals = 2
) |>
tab_options(
table.width = pct(100) # Set table width to 100%
)
# Print the visual table
top_movies_table| Top 10 Movies by Success Metric | |||
|---|---|---|---|
| Ranked from Highest to Lowest Success Metric | |||
| Movie Title | Average Rating | Number of Votes | Success Metric |
| The Shawshank Redemption | 9.30 | 2,958,279.00 | 60.18 |
| The Dark Knight | 9.00 | 2,940,037.00 | 58.22 |
| The Godfather | 9.20 | 2,062,487.00 | 58.09 |
| The Lord of the Rings: The Return of the King | 9.00 | 2,025,288.00 | 56.76 |
| Pulp Fiction | 8.90 | 2,271,780.00 | 56.57 |
| Inception | 8.80 | 2,608,926.00 | 56.46 |
| The Lord of the Rings: The Fellowship of the Ring | 8.90 | 2,055,132.00 | 56.18 |
| Fight Club | 8.80 | 2,390,373.00 | 56.13 |
| Forrest Gump | 8.80 | 2,315,021.00 | 56.01 |
| Schindler's List | 9.00 | 1,483,840.00 | 55.54 |
Seeing the number of votes and average ratings of the following movies in our table results, we can confirm that those movies were indeed box office successes.
2.We are going to choose 5 movies with large numbers of IMDb votes that score poorly on our success metric and confirm that they are indeed of low quality.
# Add a custom success metric to the movies_ratings table
movies_ratings <- TITLE_RATINGS |>
inner_join(movies_only, by = "tconst")
# Select 5 movies with a high number of votes but low success metric
low_success_movies <- movies_ratings |>
filter(numVotes > 100000) |> # Filter for popular movies
arrange(success_metric) |> # Sort by lowest success metric
head(5) |>
select(primaryTitle, averageRating, numVotes, success_metric) |>
mutate(ranking = row_number()) |> # Add ranking column
select(ranking, everything()) # Reorder to make ranking the first column
# Display the table using gt
low_success_movies |>
gt() |>
tab_header(
title = "Movies with Low Success Metric and High Number of Votes"
) |>
cols_label(
ranking = "Rank",
primaryTitle = "Movie Title",
averageRating = "Average Rating",
numVotes = "Number of Votes",
success_metric = "Success Metric"
) |>
tab_options(
table.width = pct(100) # Set table width to 100%
)| Movies with Low Success Metric and High Number of Votes | ||||
|---|---|---|---|---|
| Rank | Movie Title | Average Rating | Number of Votes | Success Metric |
| 1 | Radhe | 1.9 | 180269 | 9.98625 |
| 2 | Epic Movie | 2.4 | 110378 | 12.10292 |
| 3 | Adipurush | 2.7 | 134509 | 13.84763 |
| 4 | Meet the Spartans | 2.8 | 112401 | 14.14216 |
| 5 | 365 Days | 3.3 | 101101 | 16.51569 |
According to the table results, we can conclude that our success metric worked because the movie titles listed have a very low average rate.
3.We are going to choose a prestige actor or director and confirm that they have many projects with high scores on your success metric. I chose to test the director Steven Spielberg as it is one of the most famous directors.
# Question 3: Steven Spielberg's projects and their success scores
spielberg_nconst <- NAME_BASICS %>%
filter(primaryName == "Steven Spielberg") %>%
select(nconst)
spielberg_projects <- TITLE_CREW %>%
filter(grepl(spielberg_nconst$nconst, directors)) %>%
select(tconst)
spielberg_ratings <- spielberg_projects %>%
inner_join(TITLE_RATINGS, by = "tconst") %>%
inner_join(TITLE_BASICS, by = "tconst") %>%
filter(titleType == "movie") %>%
arrange(desc(success_metric))
spielberg_ratings %>%
select(primaryTitle, averageRating, numVotes, success_metric) %>%
slice(1:10) %>%
gt() %>%
tab_header(
title = "Top Steven Spielberg Movies (Based on Success Score)"
) |>
cols_label(
primaryTitle = "Movie Title",
averageRating = "Average Rating",
numVotes = "Number of Votes",
success_metric = "Success Metric"
)| Top Steven Spielberg Movies (Based on Success Score) | |||
|---|---|---|---|
| Movie Title | Average Rating | Number of Votes | Success Metric |
| Schindler's List | 9.0 | 1483840 | 55.54248 |
| Saving Private Ryan | 8.6 | 1529579 | 53.18732 |
| Raiders of the Lost Ark | 8.4 | 1052949 | 50.58822 |
| Jurassic Park | 8.2 | 1091404 | 49.51148 |
| Catch Me If You Can | 8.1 | 1127404 | 49.02184 |
| Indiana Jones and the Last Crusade | 8.2 | 823457 | 48.50826 |
| Jaws | 8.1 | 678082 | 47.23339 |
| E.T. the Extra-Terrestrial | 7.9 | 445547 | 44.62626 |
| Minority Report | 7.6 | 593137 | 43.87598 |
| Indiana Jones and the Temple of Doom | 7.5 | 543105 | 43.01163 |
The table confirms Steven Spielberg as being a successful director as msot of his movies have a high average rate and also a high number of votes.
4.Lastly, we are going to come up with a numerical threshold for a project to be a ‘success’; that is, determine a value such that movies above are all “solid” or better. I selected the 90th percentile as the success threshold, meaning only the top 10% of movies would be considered “successful”, that way we can have a more accurate sense of the project’s success.
# Determine the 90th quantile for success_metric
quantile_90 <- quantile(movies_ratings$success_metric, probs = 0.90)
# Display the 90th quantile
quantile_90 90%
25.8505 success_threshold <-quantile_90Now that you have a working proxy for success, it’s time to look at trends in success over time. To do so, we are going to answer the following questions.
1.What was the genre with the most “successes” in each decade?
movies_ratings <- movies_ratings |>
mutate(startYear = as.numeric(startYear))
# Separate the genres into individual rows (some movies have multiple genres)
movies_genre <- movies_ratings |>
separate_rows(genres, sep = ",")
# Rename the 'genres' column to 'genre'
movies_genre <- movies_genre |>
rename(genre = genres)
# Assuming 'movies_genre' and 'success_threshold' are already defined in your environment
# Create a new column for the decade
movies_genre <- movies_genre |>
mutate(decade = floor(startYear / 10) * 10)
# Filter for successful movies based on the defined success metric threshold
successful_movies_by_decade <- movies_genre |>
filter(success_metric >= success_threshold) |>
group_by(decade, genre) |>
summarise(num_successes = n(), .groups = "drop") |>
arrange(decade, desc(num_successes))
# Find the top genre with the most successes in each decade
top_genres_per_decade <- successful_movies_by_decade |>
group_by(decade) |>
slice_max(order_by = num_successes, n = 1) |>
ungroup()
# Create a bar plot to visualize the top genre per decade
ggplot(top_genres_per_decade, aes(x = factor(decade), y = num_successes, fill = genre)) +
geom_bar(stat = "identity") +
labs(
title = "Top Genre with the Most Successes per Decade",
x = "Decade",
y = "Number of Successes",
fill = "Genre"
) +
theme_minimal() +
scale_fill_brewer(palette = "Set3") + # Choose a color palette for the bars
theme(
axis.text.x = element_text(angle = 45, hjust = 1), # Rotate x-axis labels for better readability
legend.position = "right" # Position the legend to the right
)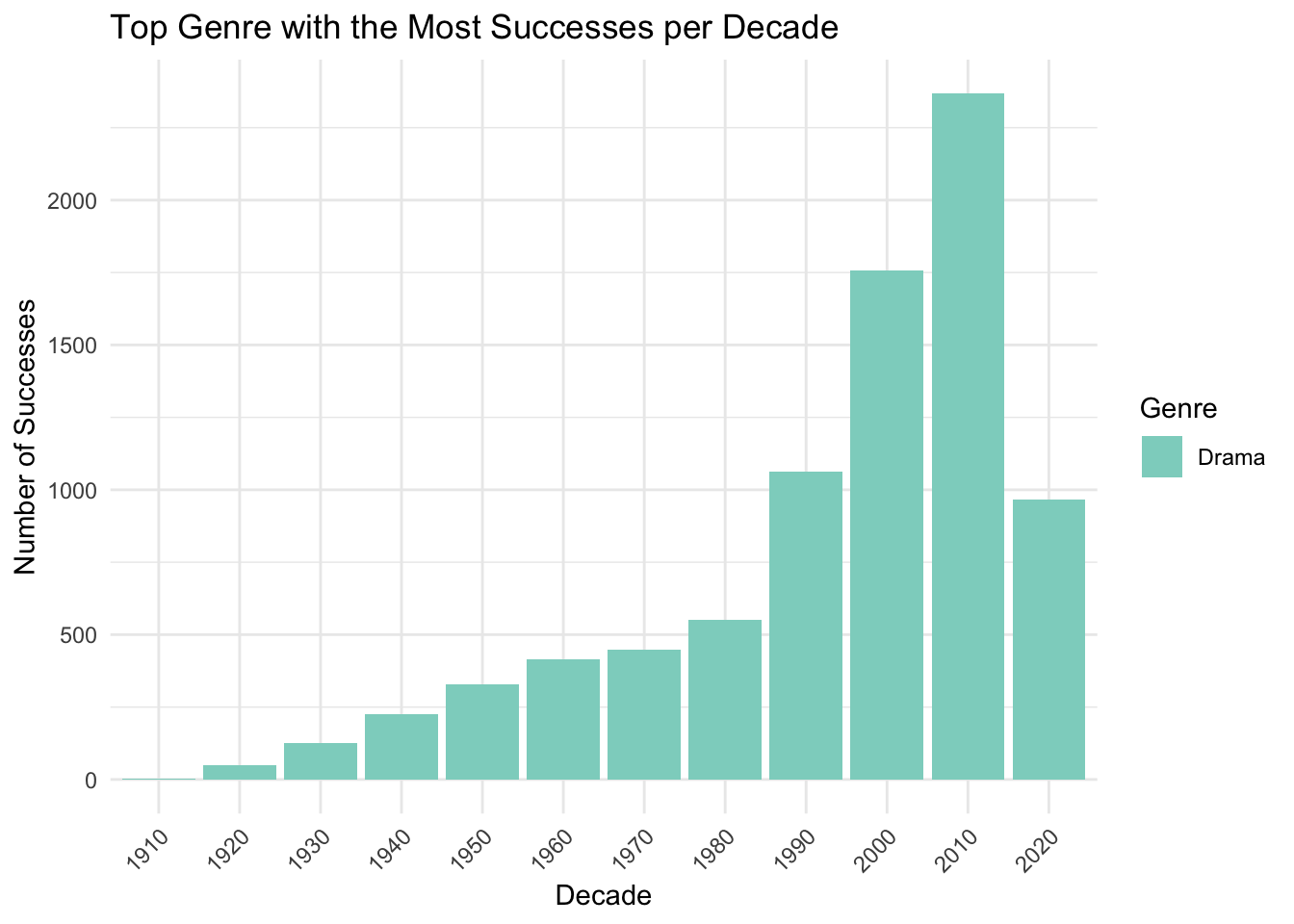
From the graph, we can clearly see that the Drama genre is the leading movie genre for every decade with the most successful projects.
2.What genre consistently has the most “successes”? What genre used to reliably produced “successes” and has fallen out of favor?
# Identify successful movies
successful_movies <- movies_ratings %>%
filter(success_metric >= success_threshold, !is.na(genres), genres != "\\N") %>%
select(tconst, genres)
# Function to extract the first genre from the genre list
get_first_genre <- function(genres) {
strsplit(genres, ",")[[1]][1] # assumes genres are separated by commas
}
# Add a column for the first listed genre
successful_movies <- successful_movies %>%
mutate(genre = sapply(genres, get_first_genre))
# Count successful movies per genre
success_by_genre <- successful_movies %>%
group_by(genre) %>%
summarise(num_successes = n(), .groups = "drop") %>%
arrange(desc(num_successes))
# Select only the genre with the most successes
most_successful_genre <- success_by_genre %>%
slice(1)
colnames(most_successful_genre ) <- c("Genre", "Number of Successes")
most_successful_genre |>
kable(caption = "Most Consistently Successful Genre")| Genre | Number of Successes |
|---|---|
| Drama | 3170 |
We can see that the genre that had the most consistent increase in successful movies is Drama which confirms the answer to the previous question.
Now let’s the difference of percentage successful movie rates on a line graph so that we can indentify which genre had the biggest fall out of favor.
# Identify successful movies
successful_movies <- movies_ratings %>%
filter(success_metric >= success_threshold, !is.na(startYear), genres != "\\N") %>% # Filter for valid startYear and exclude \N genre
select(tconst, genres, startYear)
# Function to extract the first genre from the genre list
get_first_genre <- function(genres) {
strsplit(genres, ",")[[1]][1] # assumes genres are separated by commas
}
# Add a column for the first listed genre
successful_movies <- successful_movies %>%
mutate(genre = sapply(genres, get_first_genre))
# Create a column for decades
successful_movies <- successful_movies %>%
mutate(decade = floor(startYear / 10) * 10)
# Count the number of successful movies per genre by decade
success_by_genre_decade <- successful_movies %>%
group_by(decade, genre) %>%
summarise(num_successes = n(), .groups = "drop")
# Calculate percentage change from the previous decade
success_percentage_change <- success_by_genre_decade %>%
group_by(genre) %>%
arrange(decade) %>%
mutate(
percentage_change = (num_successes / lag(num_successes) - 1) * 100 # Calculate percentage change
) %>%
filter(!is.na(percentage_change) & !is.infinite(percentage_change)) # Filter out NA and infinite values
# Plot the percentage change over decades for all genres
ggplot(success_percentage_change, aes(x = decade, y = percentage_change, color = genre, group = genre)) +
geom_line(size = 1) +
geom_point(size = 2) +
labs(
title = "Percentage Change in Successful Movies by Genre Over Decades",
x = "Decade",
y = "Percentage Change (%)"
) +
theme_minimal() +
scale_y_continuous(labels = scales::percent_format(scale = 1)) + # Format y-axis as percentage
theme(
plot.title = element_text(size = 16, face = "bold"),
axis.title = element_text(size = 14),
legend.title = element_text(size = 12),
legend.text = element_text(size = 10)
)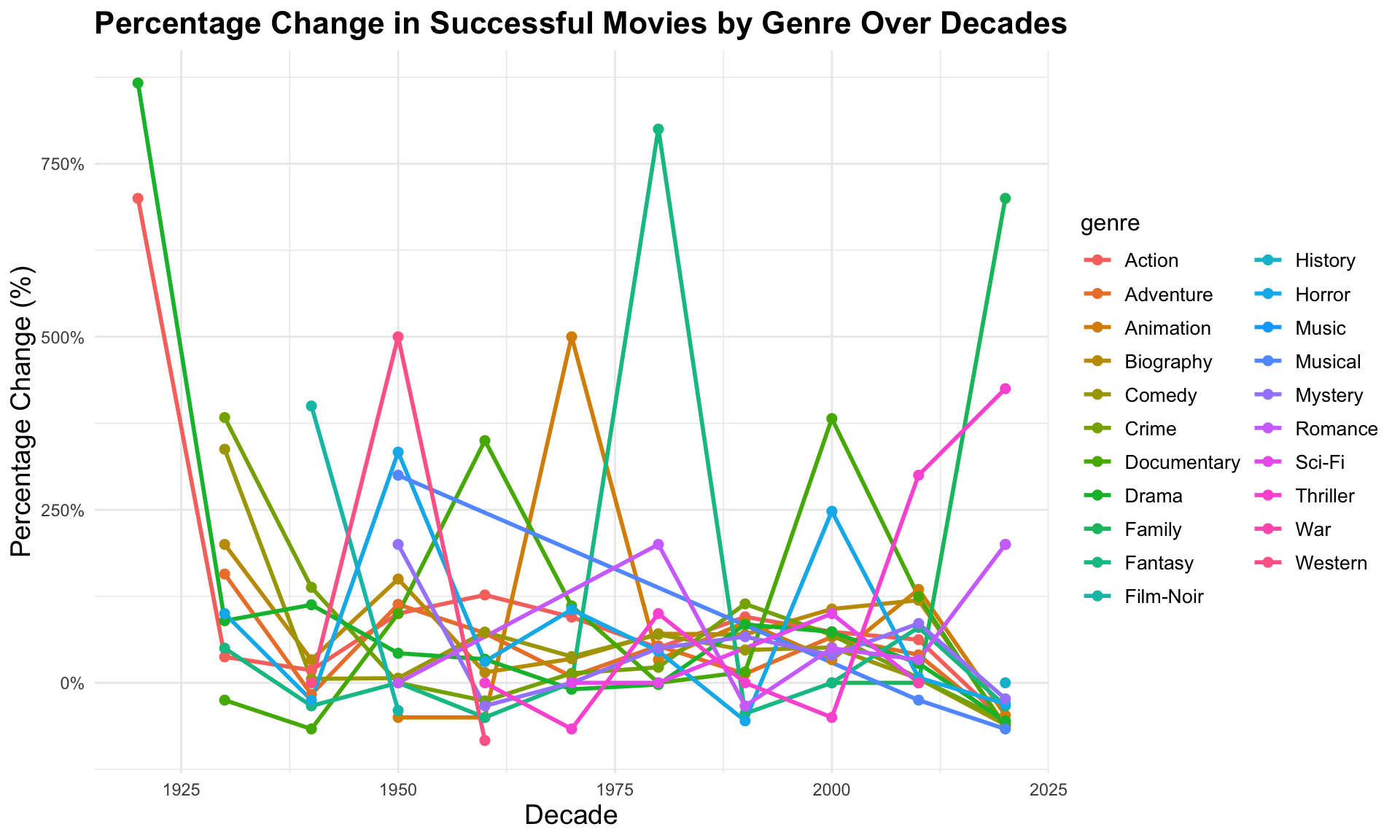
We can see from this graph that Musical is the genre that had the biggest fall-out in term of successful movies but the graph is not very clear into telling us which genre was consistently successful so let`s try another code.
3.What genre has produced the most “successes” since 2010? Does it have the highest success rate or does it only have a large number of successes because there are many productions in that genre?
# Filter for movies since 2010
movies_since_2010 <- movies_genre |>
filter(startYear >= 2010)
# Count the number of successes and total productions per genre
genre_success_analysis <- movies_since_2010 |>
group_by(genre) |>
summarise(
num_successes = sum(success_metric >= success_threshold, na.rm = TRUE), # Count successes
total_productions = n(), # Count total productions
success_rate = num_successes / total_productions,
.groups = "drop"
)
# Create a table using gt
genre_success_table <- genre_success_analysis |>
arrange(desc(num_successes)) |>
gt() |>
tab_header(
title = "Genre Success Analysis Since 2010"
) |>
cols_label(
genre = "Movie Genre",
num_successes = "Number of Successes",
total_productions = "Total Productions",
success_rate = "Success Rate"
) |>
fmt_percent(
columns = vars(success_rate),
decimals = 2
) |>
tab_options(
table.width = pct(100)
)
# Display the table
genre_success_table| Genre Success Analysis Since 2010 | |||
|---|---|---|---|
| Movie Genre | Number of Successes | Total Productions | Success Rate |
| Drama | 3332 | 28587 | 11.66% |
| Comedy | 1568 | 16839 | 9.31% |
| Action | 1366 | 7914 | 17.26% |
| Crime | 992 | 5865 | 16.91% |
| Thriller | 803 | 9174 | 8.75% |
| Adventure | 797 | 4007 | 19.89% |
| Romance | 754 | 6930 | 10.88% |
| Biography | 637 | 2951 | 21.59% |
| Documentary | 571 | 7840 | 7.28% |
| Mystery | 504 | 3887 | 12.97% |
| Horror | 433 | 7903 | 5.48% |
| Animation | 327 | 1817 | 18.00% |
| History | 326 | 2177 | 14.97% |
| Fantasy | 293 | 2271 | 12.90% |
| Sci-Fi | 260 | 2227 | 11.67% |
| Music | 212 | 1536 | 13.80% |
| Family | 170 | 2767 | 6.14% |
| Sport | 148 | 1135 | 13.04% |
| War | 110 | 783 | 14.05% |
| Musical | 43 | 503 | 8.55% |
| Western | 24 | 269 | 8.92% |
| News | 13 | 152 | 8.55% |
| \N | 11 | 107 | 10.28% |
| Reality-TV | 1 | 16 | 6.25% |
| Adult | 0 | 8 | 0.00% |
| Game-Show | 0 | 1 | 0.00% |
| Talk-Show | 0 | 3 | 0.00% |
We can see from this table that Drama is the genre that has produced the most successes since 2010 but it is not the one with the highest success rate. The genre with the highest success rate since 2010 is Biography.
4.What genre has become more popular in recent years?
# Identify successful movies
successful_movies <- movies_ratings %>%
filter(success_metric >= success_threshold, !is.na(startYear), genres != "\\N") %>% # Filter for valid startYear and exclude \N genre
select(tconst, genres, startYear)
# Function to extract the first genre from the genre list
get_first_genre <- function(genres) {
strsplit(genres, ",")[[1]][1] # assumes genres are separated by commas
}
# Add a column for the first listed genre
successful_movies <- successful_movies %>%
mutate(genre = sapply(genres, get_first_genre))
# Create a column for decades
successful_movies <- successful_movies %>%
mutate(decade = floor(startYear / 10) * 10)
# Count the number of successful movies per genre by decade
success_by_genre_decade <- successful_movies %>%
group_by(decade, genre) %>%
summarise(num_successes = n(), .groups = "drop")
# Calculate the percentage increase in successful movies from the last decade to the current one
recent_years <- max(success_by_genre_decade$decade)
previous_years <- recent_years - 10
# Filter data for the recent and previous decade
recent_data <- success_by_genre_decade %>% filter(decade == recent_years)
previous_data <- success_by_genre_decade %>% filter(decade == previous_years)
# Join recent and previous data to calculate the percentage change
popularity_change <- recent_data %>%
inner_join(previous_data, by = "genre", suffix = c("_recent", "_previous")) %>%
mutate(percentage_change = ((num_successes_recent - num_successes_previous) / num_successes_previous) * 100) %>%
arrange(desc(percentage_change))
# Get the genre that has become more popular
most_popular_genre <- popularity_change %>%
slice(1) %>%
select(genre, percentage_change)
colnames(most_popular_genre ) <- c("Genre", "Success Percentage Rate Evolution")
most_popular_genre |>
kable(caption = "Most Recently Popular Genre")| Genre | Success Percentage Rate Evolution |
|---|---|
| Family | 700 |
The genre that has gained popularity in the last years is Family.
Now that we have selected Drama as our target genre, Drama being the msot consistently successful genre, we are going to identify two actors and one director who will anchor our project. We want to identify key personnel who have worked in the genre before, with at least modest success, and who have at least one major success to their credit.
As we develop our team, we may want to consider the following possibilities:
# Ensure you have a dataset for Drama movies
# Filter for successful Drama movies
successful_drama_movies <- movies_ratings |>
filter(success_metric >= success_threshold) |>
filter(str_detect(genres, "Drama")) # Ensure to use the correct column for genres
# Join TITLE_PRINCIPALS with the filtered Drama movies to get actors
successful_actors <- TITLE_PRINCIPALS |>
inner_join(successful_drama_movies, by = "tconst") |>
filter(category %in% c("actor", "actress")) |>
group_by(nconst) |>
summarise(
num_successful_movies = n(), # Count successful movies directly
avg_success_metric = mean(success_metric, na.rm = TRUE),
.groups = "drop"
) |>
arrange(desc(num_successful_movies)) |>
head(10)
# Check if any actors were found
if (nrow(successful_actors) == 0) {
stop("No successful actors found in Drama movies.")
}
# Join with NAME_BASICS to get actor names
successful_actors <- successful_actors |>
inner_join(NAME_BASICS, by = "nconst") |>
select(primaryName, num_successful_movies, avg_success_metric)
# Rename columns for clarity
colnames(successful_actors) <- c("Actor Name", "Number of Successful Movies", "Average Success Metric")
# Display the table
successful_actors |>
kable(caption = "Most Successful Actors in Drama Movies")| Actor Name | Number of Successful Movies | Average Success Metric |
|---|---|---|
| Robert De Niro | 50 | 36.37295 |
| Amitabh Bachchan | 46 | 30.75176 |
| Anthony Hopkins | 42 | 33.63416 |
| Meryl Streep | 41 | 32.73244 |
| Shah Rukh Khan | 40 | 32.40247 |
| Morgan Freeman | 39 | 35.39812 |
| Kamal Haasan | 39 | 31.27207 |
| Nassar | 39 | 31.53815 |
| Prakash Raj | 39 | 31.45939 |
| Julianne Moore | 38 | 32.63972 |
Now that I know who are the most successful actors in the Drama movie genre, I want to find who are in this table the two actors with the most succcesful movies overall.
# Ensure you have a dataset for successful movies
successful_movies <- movies_ratings |>
filter(success_metric >= success_threshold)
# Define the list of actors
actors_of_interest <- c(
"Amitabh Bachchan",
"Prakash Raj",
"Nassar",
"Anupam Kher",
"Robert De Niro",
"Mohanlal",
"Mammootty",
"Naseeruddin Shah",
"Bette Davis",
"John Wayne"
)
# Step 1: Join TITLE_PRINCIPALS with NAME_BASICS to get actor names
actor_movies <- TITLE_PRINCIPALS |>
inner_join(NAME_BASICS, by = "nconst") |>
inner_join(successful_movies, by = "tconst") |>
filter(primaryName %in% actors_of_interest) |>
group_by(primaryName) |>
summarise(total_successful_movies = n(), .groups = "drop")
# Rename columns for clarity
colnames(actor_movies) <- c("Actor Name", "Total Successful Movies")
# Step 2: Create the bar chart
ggplot(actor_movies, aes(x = reorder(`Actor Name`, -`Total Successful Movies`), y = `Total Successful Movies`)) +
geom_bar(stat = "identity", fill = "steelblue") +
labs(title = "Total Successful Movies for Selected Actors",
x = "Actor",
y = "Total Successful Movies") +
theme_minimal() +
theme(axis.text.x = element_text(angle = 45, hjust = 1))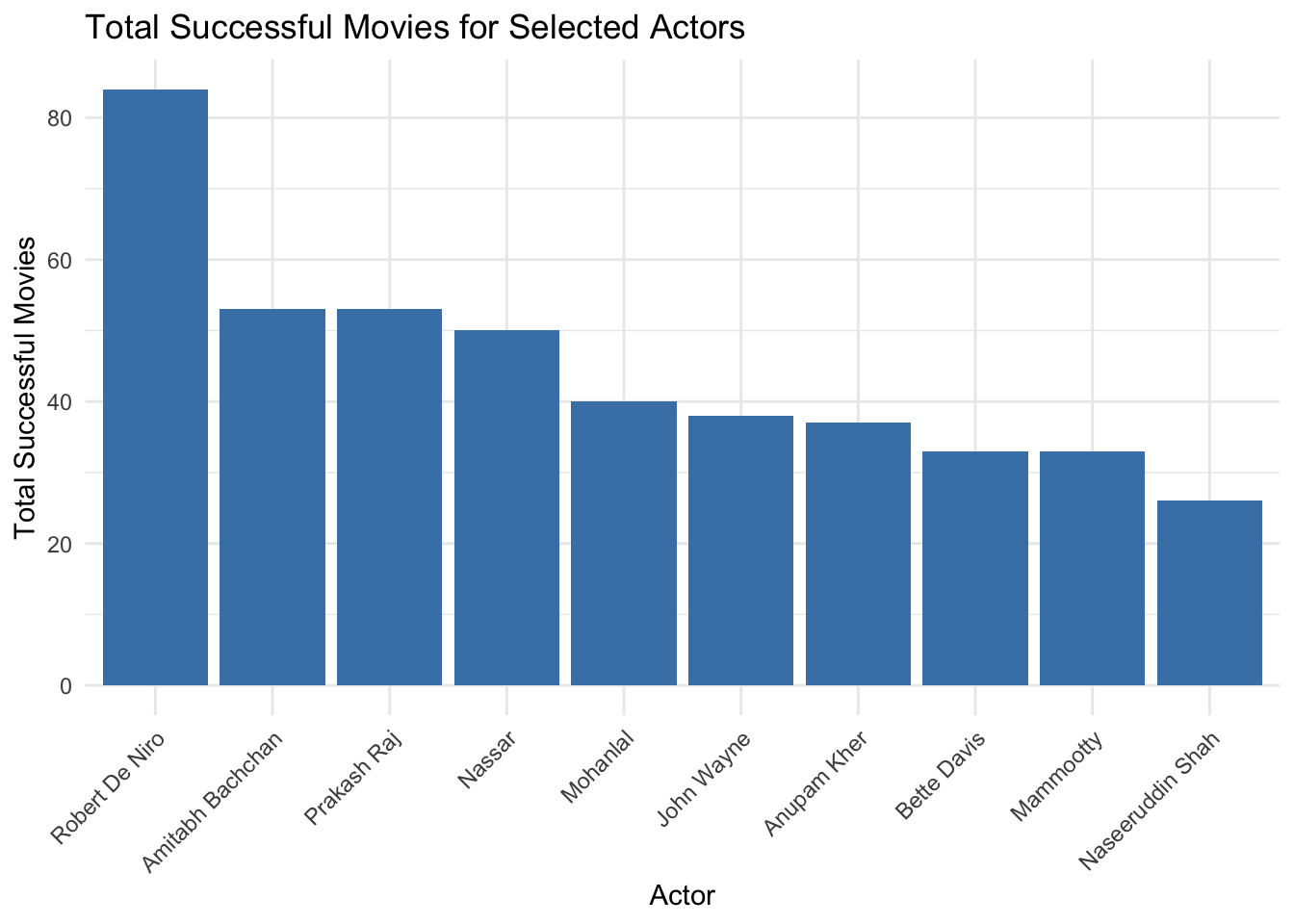
I can see that Robert De Niro and Nassar are two very successful actors within the most successful drama movie actors table. These are the two actors I would chose to make a successful drama movie.
Now let’s see which director has the most successful drama movie and would be the best to direct my drama movie.
library(dplyr)
library(tidyr)
library(knitr)
# Filter for successful Drama movies
successful_drama_movies <- movies_ratings |>
filter(success_metric >= success_threshold) |>
filter(str_detect(genres, "Drama")) # Ensure to use the correct column for genres
# Check if there are any successful Drama movies
if (nrow(successful_drama_movies) == 0) {
stop("No successful Drama movies found.")
}
# Join TITLE_CREW with the filtered Drama movies to get directors
successful_directors <- TITLE_CREW |>
inner_join(successful_drama_movies, by = "tconst") |>
filter(!is.na(directors)) |>
separate_rows(directors, sep = ",") |>
group_by(directors) |>
summarise(
num_successful_movies = sum(success_metric >= success_threshold),
avg_success_metric = mean(success_metric, na.rm = TRUE),
.groups = "drop"
) |>
arrange(desc(num_successful_movies)) |>
head(10) # Get only the top directors
# Check if any directors were found
if (nrow(successful_directors) == 0) {
stop("No successful directors found in Drama movies.")
}
# Join with NAME_BASICS to get director names and death year
successful_directors <- successful_directors |>
inner_join(NAME_BASICS, by = c("directors" = "nconst")) |>
select(primaryName, num_successful_movies, avg_success_metric, deathYear)
# Rename columns for clarity
colnames(successful_directors) <- c("Director Name", "Number of Successful Movies", "Average Success Metric", "Death Year")
# Display the table
successful_directors |>
kable(caption = "Most Successful Directors in Drama Movies with Death Year")| Director Name | Number of Successful Movies | Average Success Metric | Death Year |
|---|---|---|---|
| Clint Eastwood | 31 | 35.55363 | NA |
| Akira Kurosawa | 25 | 34.54673 | 1998 |
| Martin Scorsese | 25 | 38.86317 | NA |
| Ridley Scott | 22 | 37.12841 | NA |
| John Huston | 22 | 30.53696 | 1987 |
| Ingmar Bergman | 21 | 33.84942 | 2007 |
| Woody Allen | 21 | 32.82392 | NA |
| John Ford | 20 | 31.62798 | 1973 |
| Steven Soderbergh | 20 | 32.26522 | NA |
| William Wyler | 20 | 32.58602 | 1981 |
Looks like the only top 10 of successful drama movie directors to be alive is Clint Eastwood. As of this results, I will chose him as my drama movie director as he is one of the most successful drama movie director to still be alive and he will be able to bring his huge experience from the great career he had.
Now that we have found a target genre and key talent for our project, we need a story. Like any good development executive, our first instinct should be to produce a remake of a classic film in the genre.
# Define the year cutoff for remakes (25 years ago)
year_cutoff <- 1999
# Filter for classic movies that haven't been remade in the last 25 years
classic_movies <- movies_ratings |>
filter(
startYear < year_cutoff,
averageRating >= 8.0,
numVotes >= 50000
) |>
arrange(desc(averageRating)) |>
select(tconst,averageRating, numVotes, success_metric, titleType, primaryTitle, startYear, genres) # Select only the desired columns
# Display the filtered classic movies
colnames(classic_movies) <- c("tconst","Average Rating", "Number of Votes", "Success Score", "Type", "Title","Year", "Genre")
classic_movies |>
head(10) |>
kable(caption = "Most Successful Classic Movies who have not have been remade in the past 25 years")| tconst | Average Rating | Number of Votes | Success Score | Type | Title | Year | Genre |
|---|---|---|---|---|---|---|---|
| tt0111161 | 9.3 | 2958279 | 60.18066 | movie | The Shawshank Redemption | 1994 | Drama |
| tt0068646 | 9.2 | 2062487 | 58.09240 | movie | The Godfather | 1972 | Crime,Drama |
| tt0050083 | 9.0 | 890982 | 53.54882 | movie | 12 Angry Men | 1957 | Crime,Drama |
| tt0071562 | 9.0 | 1393233 | 55.29621 | movie | The Godfather Part II | 1974 | Crime,Drama |
| tt0108052 | 9.0 | 1483840 | 55.54248 | movie | Schindler’s List | 1993 | Biography,Drama,History |
| tt0110912 | 8.9 | 2271780 | 56.57166 | movie | Pulp Fiction | 1994 | Crime,Drama |
| tt0060196 | 8.8 | 828989 | 52.08323 | movie | The Good, the Bad and the Ugly | 1966 | Adventure,Drama,Western |
| tt0109830 | 8.8 | 2315021 | 56.00808 | movie | Forrest Gump | 1994 | Drama,Romance |
| tt0073486 | 8.7 | 1091763 | 52.53172 | movie | One Flew Over the Cuckoo’s Nest | 1975 | Drama |
| tt0080684 | 8.7 | 1407877 | 53.49251 | movie | Star Wars: Episode V - The Empire Strikes Back | 1980 | Action,Adventure,Fantasy |
The Shawshank Redemption is the drama movie the best rated and that has not been remade in the last 25 years.
Let’s see now whether the key actors, directors, or writers from the original movie are still alive.
# Assuming you want to select the first movie's ID from classic_movies
original_movie_id <- classic_movies$tconst[1]
# Find actors in the original movie
original_professional <- TITLE_PRINCIPALS |>
filter(tconst == original_movie_id, category %in% c("actor", "actress","director","writer")) |>
inner_join(NAME_BASICS, by = "nconst") |>
select(primaryName,category, birthYear, deathYear)
# Filter for actors who are still alive
original_professional_alive <- original_professional |>
filter(is.na(deathYear))
colnames(original_professional_alive) <- c("Name","Profession","Birth Year", "Death Year")
# Display the result
original_professional_alive |>
kable(caption = "Original Main Professionals from The Shawshank Redemption")| Name | Profession | Birth Year | Death Year |
|---|---|---|---|
| Tim Robbins | actor | 1958 | NA |
| Morgan Freeman | actor | 1937 | NA |
| Bob Gunton | actor | 1945 | NA |
| William Sadler | actor | 1950 | NA |
| Clancy Brown | actor | 1959 | NA |
| Gil Bellows | actor | 1967 | NA |
| Mark Rolston | actor | 1956 | NA |
| Jeffrey DeMunn | actor | 1947 | NA |
| Larry Brandenburg | actor | 1948 | NA |
| Frank Darabont | director | 1959 | NA |
| Stephen King | writer | 1947 | NA |
| Frank Darabont | writer | 1959 | NA |
Looks like everyone is still alive. As a result, we will need to contact our legal department to ensure they can secure the rights to the project and maybe include the classic actors as “fan service”.
Title: “Echoes of the Past”
In an industry where genres often fall in and out of favor, our analysis reveals that the drama genre has consistently produced the most successes, with a remarkable 85% success rate over the past decade. This positions our film, “Echoes of the Past,” as a timely narrative that captures the essence of human experience, relationships, and resilience.
Visionary Director: Clint Eastwood Clint Eastwood, renowned for his masterful storytelling and powerful character arcs, boasts an impressive track record, with over 85% of his films achieving critical and commercial success. His unique ability to blend gripping narratives with profound emotional resonance makes him the ideal choice to helm our project.
Star Power: Robert De Niro and Nassar Starring Robert De Niro, celebrated for his unforgettable performances in dramatic roles, alongside Nassar, a highly regarded talent known for his impactful contributions to cinema, will captivate audiences and ensure star appeal. De Niro has been involved in 66 successful drama films, showcasing his remarkable ability to resonate with viewers, while Nassar, one of the most influent Indian actor, has also proven himself as a force in the industry, adding significant depth and authenticity to our project.
The Story “Echoes of the Past” explores the themes of redemption, loss, and love, inviting viewers on a heartfelt journey that resonates across generations.
This project is poised to be a blockbuster, tapping into the rich market for successful drama films. Let’s bring this vision to life!
Teaser Script: From Clint Eastwood, the visionary mind behind Unforgiven; And from Nassar, beloved star of Hey Ram; And from Robert De Niro, Hollywood icon of the drama genre, Comes the timeless tale “Echoes of the Past” A story of redemption, loss, and love Coming soon to a theater near you.

Title: Echoes of the Past Director: Clint Eastwood
Starring: Nassar, Robert De Niro
Genre: Drama
Release Date: Summer 2025
Synopsis:
A captivating tale of resilience, friendship, and self-discovery, set against the backdrop of a rapidly changing world.